Failover Timing
The following illustration displays approximate timings of the FSM failover in an HA cluster. The numbers in the notes correspond to the numbers in the illustration.
In this description, both MDCs in an HA Cluster are fully started and the Secondary MDC is ready to assume the Primary role if needed. At time T0, an HA Reset of the Primary occurs.
Figure 1: FSM Failover in an HA Cluster
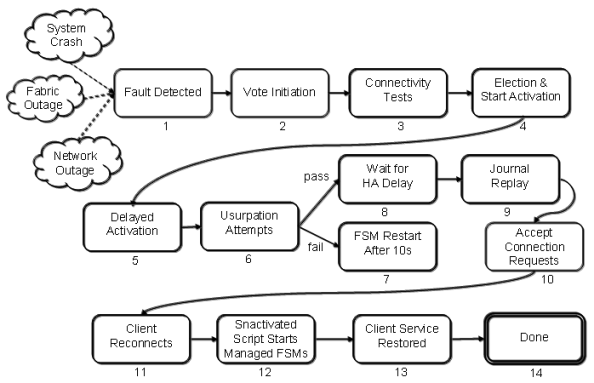
Not shown in this diagram are the state transitions of the peer MDC when it incurs an HA Reset. The HA Reset is not directly tied to the failover of control to a standby FSM, but rather the detection of a loss of services triggers failovers. The HA Reset may come before or after the loss of services, or not at all. It is only important to know that by the end of state 8, no FSM on the peer MDC is controlling the arbitration block (ARB). The HA Reset mechanism guarantees that to be true.
The example failures shown here (System Crash, Fabric Outage, Network Outage) can result in a failover. Typically, the loss of heartbeat from the peer MDC's FSMPM is the first indication that an HA Reset has occurred.
- Triggering Event: The loss of heartbeat is detected and triggers an election at approximate time T3.5 seconds. Note that failover of a single unmanaged file system could also be forced with the cvadmin command without causing an HA Reset.
- Vote Initiation: A quorum-vote election is started where the clients of the file system identify the best-connected MDC having a standby FSM for the file system.
- Connectivity Tests: Each live client runs a connectivity test sequence to each server. Connections are tested in less than .5 seconds per server, when successful, and can be repeated up to four times (two seconds) when unsuccessful. At completion of the election, the time is approximately T5.5.
- Election and Start Activation: The election is completed, and an activation message is sent to one server’s standby FSM.
- Delayed Activation: When a server has active FSMs, its FSMPM process sends a request to the FSMPM of its peer server to ask if the corresponding Standby FSMs are being activated. If not, the local FSMPM can reset the HA timer of that file system's active FSM, which reduces the chance of an unnecessary HA Reset. When the peer FSMPM gives permission, it is constrained from activating the standby FSM for two seconds. Step 5 is for that delay of up to two seconds. The delay completes at approximately T6.5.
- Usurpation Attempts: To prevent false takeovers, the ARB is polled to determine whether another FSM is active and must be "usurped". Usurpation is averted if the activating FSM detects activity in the ARB and its vote count does not exceed the active FSM's client-connection count. A typical successful poll after an HA Reset lasts two seconds. When the previously active FSM exits gracefully, the usurpation takes one second.
The activating FSM then performs a sequence of I/Os to "brand" the arbitration block to signal takeover to the peer FSM. An active FSM is required to exit when it sees that its brand has been overwritten. These operations take two seconds. The HAmon timer is started at this point if the HaFsType is HaShared or HaUnmanaged. This step completes at approximately T9.5.
- FSM Restart: After five failed attempts to usurp control, an activating FSM exits. The fsmpm restarts a standby FSM ten seconds later.
- Wait for HA Delay: When an active FSM is configured for HA Monitoring (HaShared or HaUnmanaged), and the ARB brand is not maintained for more than the HA Timer Interval (five seconds by default), the FSM's server computer is reset. After an activating FSM writes its brand, it waits one second longer than the HA Timer while monitoring its brand (HA Delay = six seconds by default), to be certain that the formerly active FSM has not resumed control of the ARB. The delay completes at approximately T13.5.
- Journal Replay: Any outstanding journal entries are replayed in order to achieve consistent metadata state. The time required for this step can vary due to several factors, but typically completes within seconds. A possible time for completion of this step is T18.5.
- Accept Connection Requests: The FSM begins to listen for client (re)connects. It waits up to 35 seconds for reconnections from any clients that have files open exclusively for writing, but this delay does not apply to the formerly active FSM's server computer. Approximate time at completion of this step is T20.5.
- Client Reconnects: The FSM begins servicing reconnects from the live clients. The clients perform a sequence of attribute state synchronization to ensure consistency with the server. Approximate time at completion of this step is T22.5.
- Start Managed FSMs: When the HaShared FSM reaches this step, it sets the Primary status for the server, which signals the FSMPM to start the HaManaged FSMs. Those FSMs then proceed through steps 1 through 14, but without the initial 3.5 second delay in step 1, and without the delay in step 8, since they are not HA Monitored. Activation of the HaManaged file systems can complete in seconds, completing at approximately T27.5.
- Client Service Restored: The clients reinitiate any outstanding RPCs to the server and restore full service to the applications. This runs in parallel with starting HaManaged FSMs.
- Done: At this point, processes on clients can create, read, write etc. files in StorNext file systems unless Storage Manager Services are needed. In that case there can be a delay of several minutes as those services are restarted before certain file system operations can be completed.
- The approximate time of 27.5 seconds to complete a failover is variable and could take less or significantly more time.
It is important to note that an HA Reset is possible on the Secondary server if an HaUnmanaged FSM is active there and fails to maintain its brand on the ARB within the timing constraints of the HA system.
The following table presents common timing estimates for failover of all file systems following an HA Reset of the Primary server. Actual performance will vary according to: differences in configurations; file system activities in progress at the time of failover; CPU, SAN and LAN loads, latency and health; and the nature of the conditions that caused the failover. The optimal estimates are for a forced failover at the command line of a single unmanaged file system without an HA Reset.
| Failover Timing Estimates (seconds) | ||
|---|---|---|
| State | Optimal | Common |
| 1 | 0 | 3.5 |
| 2 | 0 | 0 |
| 3 | 0.5 | 2 |
| 4 | 0 | 0 |
| 5 | 0 | 1 |
| 6 | 3 | 3 |
| 7 | n/a | n/a |
| 8 | 0 | 4 |
| 9 | 1 | 5 |
| 10 | 0.5 | 2 |
| 11 | 0.5 | 2 |
| 12 | 0 | 5 |
| 13 | 0 | 2 |
| 14 | n/a | n/a |
| Total | 5.5 | 27.5 |
