Manage Events
Important Information
You must respond to all CRITICAL events immediately. To configure the system to notify you about CRITICAL events, see Change email notifications in Monitoring System Events.
The Events page provides near-real-time system events (messages). You can filter the list by selecting filters from the pull-down menus. Available filters:
Table 1: Event Filters
|
Item |
Description |
|---|---|
|
Severity |
Filters the events list by the chosen severity level. |
|
Active |
Filters the events list by active/inactive status. |
|
Sites |
On multi-site systems, filters events by site name. |
|
Racks |
Filters the events list by rack name. |
|
Machines |
Filters the events list by host name. |
|
Time range |
Filters the events list by the chosen day, week, or month. |
|
Date range |
Filters the events list by a specified start and end date. |
The system deduplicates events by updating the number of occurrences and the time stamp of the last occurrence of an existing event, instead of creating a new event. It only deduplicates events which meet all of the following properties:
Identical event type
Same severity
Same source/machine
Same event message
The events must also occur within the dedupe period. For example, an event X has a dedupe period of 15 minutes. When X occurs within 15 minutes of its last occurrence, the system updates its Occurrences and Last occurrence properties. If X occurs beyond the dedupe period, the system adds a new event to the event list. The dedupe period is always counted from the first occurrence of the event.
Events are classified into severity levels:
Table 2: Event severity levels in descending order
|
Symbol |
Severity |
Action needed |
|---|---|---|
|
|
CRITICAL |
An issue needs immediate resolution. The issue can cause data loss or service unavailability. |
|
|
ERROR |
A hardware or software component is failing and needs attention. There is no data impact. |
|
|
WARNING |
An issue requires attention but does not immediately require an intervention. There is no data impact. The issue should be fairly easy to resolve. |
|
|
INFO |
Informational event. No action required. |



-
Click Events.
Figure 1: Events
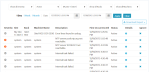
(Optional) Filter the event list by severity, status, site, and so on.
-
Click Apply.
-
(Optional) Double-click an event to see its details.
-
(Optional) Click Download Report and choose the format of the report.

-
Click Events.
-
Click X in the Ignore column of the event.
Events and Recommended Actions
This section provides the recommended actions for events.
The following table provides the critical event ID, message details, and the recommended action.
Note: Support personnel can use this link for more information on the event
Table 3: Critical events and recommended actions
|
ID |
Message and details |
Recommended action |
Dedupe interval (seconds) |
|
ABNORMAL_LOGFILE_GROWTH_DETECTED |
Abnormal log file size detected for logfile. Reached filesize MiB since last log rotation. No degradation to system functionality or system redundancy is expected. |
The event could indicate A misconfiguration of a daemon (daemon in debug mode, configuration issue in network connection pooling, ...) A log file running full with errors A DoS attack opening connections to one of our interfaces Issues with log rotation or the cron daemon running the log rotation Contact Quantum Support for help with troubleshooting. |
3600 |
|
NO_AVAILABLE_COLUMN_RESOURCES |
System capacity full. All storage columns are full and are now in READ_ONLY mode. Any new object upload will fail due to insufficient capacity. |
All storage columns are full or not available for new writes. Storage write operations will fail as long as this situation persists. Recommended action - Increase storage capacity scaling up or out, or free up storage capacity by deleting data. Space reclamation may take up to 24 hours to begin. Contact Quantum support for assistance in reclaiming storage capacity sooner. |
3600 |
|
ARAKOON_CLUSTER_NO_MASTER |
Metadata store cluster has no master. Details: Arakoon cluster cluster_id has no master. This implies that more than two nodes of this cluster have issues. |
Contact Quantum Support.Contact Quantum Support. |
3600 |
|
ARAKOON_DOWN |
Metadata store instance was down and could not be restarted. |
Check for disk failures and if disks are decommissioned, replace the disks. If there are no disk failures and if the problem is persistent, contact Quantum Support. |
3600 |
|
ARAKOON_NODE_UNRESPONSIVE |
Metadata store instance is running but unresponsive. Details: Arakoon instance node_id in cluster cluster_id is not responding to ping requests: msg |
Contact Quantum Support.
|
3600 |
| COLD_STORAGE_TAPE_MISSING | Tape media is missing. One or more tape media that was expected to be in the system seems to be missing. One or more tape media are not found in the tape libraries connected to tape gateway gateway_name (gateway_id). Please reinsert tape media with following barcodes: barcodes within the next period or a repair will be triggered. | Reinsert the tape media with the listed barcodes as soon as possible. | 86400 |
| COLD_STORAGE_RAS_TICKET | Active RAS tickets found on tape library library_name. Tape library library_name has ticket_count active RAS tickets with severity ticket_severity or higher that need attention. | Please visit the library url to view more details about these tickets. | 86400 |
|
DISK_FS_MISSING |
Filesystem missing. A degradation to application or storage redundancy may be experienced as a result of this event. Details: Filesystem on disk device: device, with label: label, with mount point: mountpoint, fstype expected: fstype_expected, fstype found:fstype_found |
Contact Quantum Support.
|
3600 |
|
DISK_FS_NOT_MOUNTED |
File system label not mounted on mountpoint. A degradation to application or storage redundancy may be experienced as a result of this event. |
Contact Quantum Support.
|
3600 |
|
DISK_NOT_FOUND |
Disk device with diskid diskid not found. A degradation of individual storage operations may occur for a short period of time. |
Contact Quantum Support.
|
3600 |
|
DISK_DETECTED |
Disk is detected |
Contact Quantum Support. |
86400 |
|
DISK_RAID_DEGRADED |
Software RAID degraded. No degradation to system functionality or system redundancy is expected. |
Check for disk failures. If this is the case wait for the disks to be automatically decommissioned and replace the disks. If there are no disk failures and if the problem is persistent, contact Quantum Support.
|
3600 |
|
DSS_STORAGEPOOL_DISK_SAFETY |
number objects are below the expected disk safety policy and indicate a reduction of storage redundancy. Details: lowest disk safety: lowest_disk_safety, site: site, rack: rack. |
If expected repair window was exceeded, contact Quantum Support.
|
3600 |
|
DSS_STORAGEPOOL_UNVERIFIED_OBJECTS |
number unverified objects are found. A degradation to storage redundancy may occur due to unnoticed bit rot if the number doesn't decrease in subsequent alerts or the alert doesn't stop altogether |
If persistent, contact Quantum Support.
|
3600 |
|
DSS_USAGE_EXCEEDED_THRESHOLD_2 |
All columns exceed the usage threshold of 90%. No degradation to system functionality or redundancy is expected. |
Purchase additional storage capacity by scaling up or out.
|
3600 |
|
ELASTICSEARCH_CLUSTER_HEALTH_STATUS_CRITICAL |
Metrics database: critical health status. This may cause metrics to fail to show in the UI, slow UI performance, and failures polling SNMP data. It may also result in events indicating Internal Task Errors. Details: At least one primary shard (and all of its replicas) is missing. Searches will return partial results. |
If this event occurs immediately after the configuration wizard completes (at initial bringup), it can be safely ignored. Otherwise, contact Quantum Support.
|
3600 |
|
ENCLOSURE_DISKGROUPS_MOVED |
Disk groups from enclosure serial (guid) moved from their original position (group_id) to another position. A degradation of overall system storage performance may be experienced as a result of this event. Details: Disk groups from enclosure with serial number serial and guid guid on bus location buslocation moved from their original group_id to a different group_id. Disk group configuration of enclosure serial is expected to be expected_config (diskgroup group_id: diskgroup serial). Current diskgroup configuration is current_config. |
Contact Quantum Support.
|
3600 |
|
ENCLOSURE_DISKS_MOVED |
Disks from enclosure serial (guid) moved from their original position (enclosure/diskgroup) to another position. A degradation of overall system storage performance may be experienced as a result of this event. Details: Disks from enclosure with serial number serial and guid guid on bus location buslocation moved from their original enclosure/ diskgroup to another enclosure/diskgroup. Disk configuration of enclosure serial is expected to be expected_config (disk guid: diskgroup serial: enclosure serial). Current disk configuration is current_config. |
Contact Quantum Support.
|
3600 |
|
ENCLOSURE_MOVED |
Enclosure serial (guid) moved from bus location buslocation to bus location new_buslocation. A degradation of overall system storage performance may be experienced as a result of this event. Details: Enclosure with serial number serial and guid guid moved from its original bus location buslocation to another bus location new_buslocation. Enclosure serial should be on bus location buslocation. |
Contact Quantum Support.
|
3600 |
|
FILEMANAGER_CLEANUP_FAILED |
File system cleanup could not free up enough (threshold%) space in mountpoint A degradation to application or storage redundancy may be experienced as a result of this event. |
Contact Quantum Support.
|
3600 |
|
FILESYSTEM_READONLY |
File system is mounted as read only. A degradation to management services or storage operations may be expected. Details: File system label: label |
Contact Quantum Support.
|
3600 |
|
FILESYSTEM_USAGE_EXCEEDED |
File system (mountpoint) usage exceeded threshold of threshold%. No degradation to system functionality or system redundancy is expected. Details: File system label: label |
Contact Quantum Support.
|
3600 |
|
FILESYSTEM_USAGE_EXCEEDED_CRITICAL |
File system label usage exceeded threshold of threshold%. If not addressed, a degradation to management services or storage operations may be experienced. Details: File system label: label |
Contact Quantum Support.
|
3600 |
|
GENERIC_DISK_SMART_FAILURE |
Generic Disk device with diskid diskid: Hard disk S.M.A.R.T. status bad. Details: smart_output |
Disk needs to be replaced after decommissioning. Contact Quantum Support. |
3600 |
|
GENERIC_IO_ERRORS |
Generic Disk device with diskid diskid: IO errors detected Details: log_lines |
Disk needs to be replaced after decommissioning. Contact Quantum Support. |
3600 |
|
HAPROXY_DOWN |
High availability gateway down and could not be restarted. S3 traffic will be impacted on this system node. |
Contact Quantum Support.
|
3600 |
|
INTERNAL_INCONSISTENCY_DETECTED |
An internal background process detected an inconsistency |
Contact Quantum Support. |
86400 |
|
INVALID_DISKGROUP_DETECTED |
The replaced SLED serial number cannot be found in the current configuration. |
Check whether all disk groups (SLEDs) are placed in the correct enclosure. If it is unclear how to proceed Contact Quantum Support. |
3600 |
|
INVENTORYSCAN_FAILED |
Inventory scanner failed. If this alert persists, system functionality to decommission and initialize disks as well as monitor other hardware may be degraded Details: inventory scanner (command) failed: output |
Contact Quantum Support.
|
3600 |
|
LOCAL_ELASTICSEARCH_HEALTH_STATUS_CRITICAL |
elasticsearch service in name is in critical condition. This may cause metrics to fail to show in the UI, slow UI performance, and failures polling SNMP data. It may also result in events indicating Internal Task Errors. Details: elasticsearch service in name is not responsive or system resources usage is too high. |
Contact Quantum Support.
|
900 |
|
MACHINE_DOWN |
Machine name is down. A degradation to individual storage operations and system redundancy may be expected until the system has been recovered. Details: machineguid GUID : IP addresses: ipaddresses |
If the node cannot be powered on, contact Quantum Support.
|
3600 |
|
MACHINE_FROZEN |
Machine name is in a frozen state. A degradation to individual storage operations and system redundancy may be expected until the system has been recovered. Details: Machine guid: GUID |
Contact Quantum Support.
|
|
|
MACHINE_UNREACHABLE |
Machine name cannot be reached from connecting_machine_name. A degradation to individual storage operations, performance, and system redundancy may be expected until the system has been recovered. Details: machineguid GUID : IP addresses: ipaddresses |
Contact Quantum Support.
|
3600 |
|
MEMORY_ERRORS |
message = Detected memory_error_type memory errors on DIMM dimm. Details = Machine guid: guid, IPMI address: ipmi, DIMM dimm. detailed_description_of_observed_errors |
Contact Quantum Support to schedule replacement. |
86400 |
|
META_DISK_SMART_FAILURE |
Metadata disk device with diskid diskid: Hard disk S.M.A.R.T. status bad. A degradation of individual storage operations may occur for a short period of time. Details: smart_output |
Disk needs to be replaced after decommissioning. Contact Quantum Support.
|
3600 |
| META_IO_DEGRADATION |
Data disk {device} with diskid {diskid}: degradation detected. A degradation of individual storage operations may occur for a short period of time. Details: diskid: {diskid}, device:{device}, buslocation:{buslocation}, serial:{serial}, type:{disktype}, size:{size} {unit}. Reason: {reason} |
Disk needs to be replaced after it has been automatically decommissioned. Contact Quantum Support. | 36000 |
|
META_IO_ERRORS |
Metadata disk device with diskid diskid: IO errors detected. A degradation of individual storage operations may occur for a short period of time. Details: log_lines |
Wait for the system to autodecommission the disk. If the disk is customer-replaceable, you can replace it after it's decommissioned. Otherwise, contact Quantum Support to replace it.
|
3600 |
|
METADATA_ISSUE |
Metadata is no longer accessible or metadata durability might be at risk. A degradation of individual storage operations may occur for a short period of time. |
Contact Quantum Support.
|
3600 |
|
METADATASERVER_DOWN |
Metadata store instance was down. A degradation of individual storage operations may occur for a very short time period. This should be corrected quickly to restore service redundancy to the metadata store. |
Check for disk failures and if disks are decommissioned, replace the disks. If there are no disk failures and if the problem is persistent, please contact Support. |
3600 |
|
MONGODB_DOWN |
Management db instance was down and could not be restarted. A degradation of data and management operations may occur. |
Check for disk failures and if disks are decommissioned, replace the disks. If there are no disk failures and if the problem is persistent, contact Quantum Support.
|
3600 |
|
MULTIPLE_PSU_ERROR |
More than one PSU error detected in rack systemName |
Check for PDU failures which can cause multiple PSU failure. If persistent, contact Quantum Support. |
3600 |
|
NTP_DOWN |
Internal ntp service is down. A degradation to application redundancy or storage operations may be experienced if the issue persists over time. |
Contact Quantum Support.
|
3600 |
|
NTP_SERVER_NOT_REACHABLE |
NTP server remote_ntp_server not reachable. If only a single NTP server has been configured, a degradation to application redundancy or storage operations may be experienced if the issue persists over time. |
Contact Quantum Support.
|
3600 |
|
NTP_UNEXPECTED_REPLY |
Internal ntp processing error. A degradation to application redundancy or storage operations may be experienced if the issue persists over time. |
Contact Quantum Support.
|
3600 |
|
OS_DISK_SMART_FAILURE |
OS Disk device with diskid diskid: Hard disk S.M.A.R.T. status bad. No degradation to system functionality or redundancy is expected. Details: smart_output |
Disk needs to be replaced after decommissioning. Contact Quantum Support.
|
3600 |
| OS_IO_DEGRADATION |
OS disk {device} with diskid {diskid}: degradation detected. Details: diskid: {diskid}, device:{device}, buslocation:{buslocation}, serial:{serial}, type:{disktype}, size:{size} {unit}. Reason: {reason} |
Disk needs to be replaced after it has been automatically decommissioned. Contact Quantum Support. | 3600 |
|
OS_IO_ERRORS |
OS Disk device with diskid diskid: IO errors detected. No degradation to system functionality or redundancy is expected. Details: log_lines |
Disk needs to be replaced after decommissioning. Contact Quantum Support.
|
3600 |
|
PDU_DOWN |
PDU name with IP ipaddress is down. Power redundancy to some systems may be degraded. |
Contact Quantum Support.
|
3600 |
|
PDU_NOT_FOUND |
PDU name with IP ipaddress is no longer detected. Power redundancy to some systems may be degraded. |
Contact Quantum Support.
|
3600 |
|
PDU_THREE_PHASE_OUT_OF_BALANCE |
PDU name with IP ipaddress 3-phase out-of-balance level is abnormal. No degradation to storage performance, system functionality or system redundancy is anticipated. |
Contact Quantum Support.
|
3600 |
|
HARD_QUOTA_EXCEEDED |
Account account_email has consumed over usage_percentage% of its allocated capacity limit of quota_gb GB. Details: Current Capacity usage: used_gb GB has exceeded the allocated quaota quota_gb GB (Usage last measured on last_updated ) Quota configuration this system for enforcement_type Threshold: Low: limit_low%, High: limit_high% Writing data to your S3 buckets and NFS exports will fail. |
Reduce capacity usage by deleting data in your S3 buckets or NFS Volumes to be able to write again. Your capacity usage will be re-evaluated within 24h. Alternatively, contact your system administrator to request additional quota. |
14400 |
|
SOFT_QUOTA_EXCEEDED |
Account account_email has consumed over usage_percentage% of its allocated capacity limit of quota_gb GB. Details: Current Capacity usage of used_gb GB has exceeded the allocated quota of quota_gb GB. (Usage last measured on last_updated). Quota configuration this system for enforcement_type Threshold: Low: limit_low%, High: limit_high% |
Reduce capacity usage by deleting data in your S3 buckets or NFS Volumes. Your capacity usage will be re-evaluated within 24h. Alternatively, contact your system administrator to request additional quota. |
14400 |
|
QUOTA_NOTIFICATION_HIGH |
Account account_email has consumed over usage_percentage% of its allocated capacity limit of quota_gb GB. Details: Current Capacity usage of used_gb GB has exceeded the allocated quota of quota_gb GB. (Usage last measured on last_updated). Quota configuration this system for enforcement_type Threshold: Low: limit_low%, High: limit_high% |
Consider reducing capacity usage by deleting files or contact your system administrator to request additional capacity. |
14400 |
|
RAID_FS_MISSING |
File system missing. A degradation to management functionality or individual storage operations may occur, however no impact to storage availability is anticipated. Details: Filesystem on raid device: devices |
Contact Quantum Support.
|
3600 |
|
RAID_FS_NOT_MOUNTED |
File system not in fstab. A degradation to application or storage redundancy may be experienced as a result of this event. Details: file system with label label on raided partition with name device and mountpoint mountpoint |
Contact Quantum Support.
|
3600 |
|
REPLICATORD_DOWN |
2-site replication service is down and could not be restarted. |
Contact Quantum Support.
|
14400 |
|
SCALERDBMGR_DOWN |
Metadata manager is down and could not be restarted. A degradation to individual storage operations may occur, however no impact to overall storage availability is anticipated. |
Check for disk failures and if disks are decommissioned, replace the disks. If there are no disk failures and if the problem is persistent, contact Quantum Support.
|
3600 |
|
SSL_EXPIRED |
SSL certificate expired: name. A degradation of data and management operations may occur. However no impact to storage availability is expected. |
Check the expiration date of your SSL certificate. If the certificate is expired, upload and new one through ActiveScale SM. If your SSL certificate is not expired, the system raised this event erroneously; contact Quantum Support.
|
3600 |
|
SWITCH_DOWN |
Switch name with IP ipaddress is not detected. A degradation of overall system storage performance may be experienced as a result of this event. |
Contact Quantum Support.
|
3600 |
|
VIP_FAILOVER_CONFLICT |
The virtual IP failover service detected conflicting network traffic. IP failover will be unreliable. |
This event indicates a problem with VIP failover management, probably caused by multiple ActiveScale systems configured with VIP failover and deployed on the same subnet. The functional consequence for applications is a likelihood of connection errors and no NFS client failover capability. Check whether there are other ActiveScale systems that have configured virtual IP failover and that are deployed on the same network segment. If there are, modify the multicast address specified when creating the failover group on one of the systems. Otherwise, contact Quantum Support. |
|
Table 4: Error events and recommended actions
|
ID |
Message and details |
Recommended action |
Dedupe interval (seconds) |
|
COREDUMPS_FOUND |
Information on application crashes found |
Contact Quantum Support. |
14400 |
|
CORLEONE_DOWN |
Business API server is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
CSGBRIDGE_DOWN |
Bucket manager down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
DISK_DECOMMISSION_FAILED |
Decommissioning of disk device with diskid disk_idfailed. Details: Decommissioning failed because of - reason |
Contact Quantum Support. |
14400 |
|
DISK_DETECTED_NOT_EMPTY |
New disk device with diskid with partitions detected and will not get provisioned automatically. Details: diskid: diskid; buslocation: buslocation; device: device |
Contact Quantum Support.
|
14400 |
|
DISK_NOT_CONFIGURED |
Disk device with diskid diskid not configured for more than num_hours hours Details: device: device; buslocation: buslocation; serial: serial |
Contact Quantum Support. |
14400 |
|
DISK_NOT_REPLACED |
Decommissioned disk with ID diskid (serial) cannot be replaced by disk with ID new_diskid (new_serial). Details: Reason that disk did not get replaced: nr_reason. Replacement disk candidate: buslocation new_bus, type new_type, size new_size new_unit, role new_role, status new_status. Decommissioned disk: buslocation buslocation, typecdisktype, size size unit, role role, status status |
Contact Quantum Support. |
14400 |
|
DISK_NOT_USED |
Disk device with diskid diskid not used for more than num_hours hours Details: device: device; buslocation: buslocation; serial: serial |
Contact Quantum Support. |
14400 |
|
DISK_PARTITION_LAYOUT_MISMATCH |
Disk device with diskid diskid has an unexpected partition layout. Possible corruption. |
Contact Quantum Support. |
14400 |
|
DISK_SMART_DISABLED |
Disk device with diskid diskid: S.M.A.R.T. capabilities disabled. Details: smart_output |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
DISKGROUP_NOT_FOUND |
Disk group group_id with serial serial not present. |
Contact Quantum Support. |
14400 |
|
DISKGROUP_UNKNOWN |
Disk group group_id with serial serial has an unknown presence status. |
Contact Quantum Support. |
14400 |
|
DOCKER_DOWN |
Plugin service is currently down. |
|
14400 |
|
DSS_DECOMMISSIONED_DISK_ERROR |
blockstore with status decommissioned for more than max_threshold days. Details: blockstore_id: blockstore_id |
Contact Quantum Support. |
14400 |
|
DSS_STORAGEPOOL_NOT_UPDATED |
dssstoragepool stats are outdated. Details: Latest update at time_last_update. Site: site |
If you see this event in the case of: Power failure or restart of a Storage Node Fresh installation Scale-up or scale-out of the system You can safely ignore this event. It should disappear after at most 48 hours. Otherwise, if the event is persistent, contact Quantum Support. |
14400 |
|
DSS_USAGE_EXCEEDED_THRESHOLD_1 |
All columns exceed the usage threshold of 80%. |
Contact Quantum Support. |
14400 |
|
DSSCLIENTDAEMON_DOWN |
dssclientdaemon is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
DSSREPAIRDAEMON_DOWN |
Storage repair service is down and could not be restarted |
Contact Quantum Support. |
14400 |
|
DSSSTORAGEDAEMON_DOWN |
Storage service is down and could not be restarted. |
Contact Quantum Support. |
14400 |
| DSS_LOCALIZED_BACKLOG_SIZE_EXCEEDED_ERROR | Based on the configured line rate of {line_rate_in_gbps} Gbps the amount of ingested data will take {days_to_clear_backlog} days to achieve full availability for data, which is above the threshold of {max_backlog_processing_days} days. The localized backlog is currently {number_of_objects} objects with a total size of {total_size_of_objects_in_gb} GiB. | Verify the WAN link status and available bandwidth against the Localized Ingest configuration and adjust if needed. If the system takes longer than the configured time to reach full availability, please either reduce incoming/outgoing data requests or disable the Localized Ingest feature. If the backlog keeps growing indefinitely, If the backlog keeps growing indefinitely, contact Quantum Support. | 3600 |
| DSS_OLDEST_LOCALIZED_OBJECT_TIME_EXCEEDED_ERROR | An object was discovered which has been uploaded on {localized_date} and still has not reached full availability, which is above the threshold of {max_backlog_processing_days} days. The localized backlog is currently {number_of_objects} objects with a total size of {total_size_of_objects_in_gb} GiB | Verify the WAN link status and available bandwidth against the Localized Ingest configuration and adjust if needed. If the system takes longer than the configured time to reach full availability, please either reduce incoming/outgoing data requests or disable the Localized Ingest feature. If the backlog keeps growing indefinitely, contact Quantum Support. | 3600 |
| ENCLOSURE_NOT_FOUND | Enclosure with serial serial at bus location buslocation is not present. | Contact Quantum Support. | 14400 |
|
FAN_ERROR |
Fan name is failing. |
Contact Quantum Support. |
14400 |
|
FAN_NOT_FOUND |
Fan name is no longer detected. |
Contact Quantum Support. |
14400 |
|
FILESYSTEM_USAGE_EXCEEDED_ERROR |
File system label usage exceeded threshold of threshold% Details: File system label: label |
Contact Quantum Support. |
14400 |
|
FLAME_CAPACITY_JOB_TIMEOUT |
Capacity count is already running for more than 24 hours. Killed it. |
If persistent, contact Quantum Support. |
14400 |
|
FLAME_JOB_FAILED |
Iteration service failed: potential problems with capacity report, encryption key report, garbage collection, object lifecycle management. |
If persistent, contact Quantum Support. |
14400 |
|
FLAME_JOB_STATUS |
No resources available for iteration service: potential problems with capacity report, encryption key report, garbage collection, object lifecycle management |
If persistent, contact Quantum Support. |
14400 |
|
FLAME_NOT_CONFIGURED |
Flame iteration service is not installed or incorrectly configured |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
FOOS_DOWN |
File daemon is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
HEKA_DOWN |
Metrics collector is down and could not be restarted |
Contact Quantum Support. |
14400 |
|
IDENTITYBRIDGE_DOWN |
Identity manager name down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
IN_SITU_REPAIR_FAILED |
In-situ repair action of disk device with diskid diskid failed. Details: Repair failed because of - reason. |
The system will recover automatically; if it does not, contact Quantum Support. |
14400 |
|
KEYROUTER_DOWN |
Metadata store gateway down |
Contact Quantum Support. |
14400 |
|
MACHINE_MODEL_CONFIG_FAILED |
Machine name (guid) model configuration failed. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
MARVINTASKMGR_DOWN |
Management task manager down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
MARVINWEB_DOWN |
Internal management application server down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
METADATASTREAMER_DOWN |
Metadatastreamer is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
MODEL_APPLICATION_CONFIG_FAILED |
Application configuration for machine 'name' (guid) failed in model API. Details: error |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
MODEL_IDENTITYBRIDGE |
Identity manager configuration error Details: details_msg |
Contact Quantum Support. |
14400 |
|
MODEL_MARVINTASKMGR |
Management layer configuration error. Details: details_msg |
Contact Quantum Support. |
14400 |
|
MODEL_MARVINWEB |
Management layer configuration error. |
Contact Quantum Support. |
14400 |
|
MODEL_MGMTSERVERS |
management servers in machine.cfg are different compared to the model. Details: details_msg |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
MODEL_NIC_CONFIG_FAILED |
Network interface configuration for machine 'name' (guid) failed in model API. Details: error |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
MODEL_RAID_CONFIG_FAILED |
RAID configuration for machine 'name' (guid) failed in model API. Details: error |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
MODEL_SCALERDBMGR |
Metadata store configuration error Details: details_msg |
Contact Quantum Support. |
14400 |
|
NFSGANESHA_DOWN |
NFS server is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
NGINX_DOWN |
nginx was down and could not be restarted. |
Contact Quantum Support.
|
14400 |
|
NIC_DOWN |
NIC device (macaddress) is down |
Contact Quantum Support. |
14400 |
|
NIC_MODEL |
Difference between NIC device with (macaddress) from NIC internal model data |
If persistent or if client applications get errors, contact Quantum Support. |
14400 |
|
NIC_NOT_FOUND |
NIC device (macaddress) is no longer detected. |
Contact Quantum Support. |
14400 |
|
NIC_WRONG_LINK_MODE |
NIC device with MAC macaddress is in the wrong link mode Details: Current link mode: current_link_speed (current_link_duplex) Expected/Highest link mode: max_link_speed (max_link_duplex) |
If persistent, contact Quantum Support. |
14400 |
|
NO_MODEL_DISK_FOR_BOOT_BUSLOCATION |
No disk detected at boot buslocation boot_buslocation. |
Contact Quantum Support.
|
14400 |
|
NON_OS_DISK_IN_BOOT_BUSLOCATION |
Boot buslocation boot_buslocation contains no bootable OS disk device. |
Contact Quantum Support. |
14400 |
|
OS_DISK_NOT_IN_BOOT_BUSLOCATION |
OS boot disk device (buslocation: buslocation) not in boot buslocation boot_buslocation. |
Contact Quantum Support. |
14400 |
|
PSU_ERROR |
PSU name is failing. |
Check to see if the PSU present. If the PSU is present: This event indicates that there is an error related to it; contact Quantum Support for further assistance. If the PSU is not present: You can safely ignore this error if you pulled out the PSU yourself temporarily (for example, if you are in the middle of a PSU replacement). Otherwise, contact Quantum Support for further assistance.
|
14400 |
|
PSU_NOT_FOUND |
PSU name is no longer detected. |
Contact Quantum Support. |
14400 |
|
RAID_INCONSISTENT |
Software raid configuration inconsistent with partitioning on disks. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
3600 |
|
RAID_MEMBERS_FAILED |
Failed members detected in software raid. Details: Raid device: {device}. {details_msg} |
Contact Quantum Support. |
14400 |
|
RAID_NUMBER_MISMATCH |
Unexpected number of raid members, expected expected_num, found real_num |
Contact Quantum Support. |
14400 |
|
RELENG_DOWN |
Reliability Engine is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
REPLICATION_BUCKET_ACL |
Replication error: Replication account does not have access to bucket bucket_name on site site. |
The bucket owner should update the Bucket ACL of bucket bucket_name on the site site to give access to replication account. |
86400 |
|
REPLICATION_BUCKET_EXISTENCE |
Replication error: Bucket bucket_name does not exist on the site site. |
Create the bucket named bucket_name on the site named site. |
86400 |
|
REPLICATION_BUCKET_VERSIONING |
Replication error: Bucket bucket_name on site site is not Versioning enabled. |
The bucket owner should enable Versioning on bucket bucket_name on the site site. |
86400 |
|
REPLICATION_OBJECT |
Replication error: Problem replicating object (replication id id). Machine machine_name: error_message. |
Contact Quantum Support. |
14400 |
|
REPLICATION_SOFTWARE_VERSION |
Replication error: The site systems software version does not allow replication. |
Upgrade to a version that supports replication. If you need assistance, contact Quantum Support. |
86400 |
|
SAMURAI_DOWN |
User interface service is down and failed to start and could not be restarted. |
Contact Quantum Support. |
14400 |
|
SCALERD_DOWN |
s3 service is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
SCALERMGMT_DOWN |
s3 management server is down and could not be restarted. |
Contact Quantum Support. |
14400 |
|
SNMPD_DOWN |
SNMP daemon is down and could not be restarted |
Contact Quantum Support. |
14400 |
|
SPARKEXECUTOR_DOWN |
sparkexecutor down and could not be restarted. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
SPARKMASTER_DOWN |
sparkmaster down and could not be restarted. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
SYSLOG_ERRORS |
Error lines found in syslog |
Look at the details of the event. If the details include any of the following messages, you can safely ignore this event: rngd: read error power_meter string: Ignoring unsafe software power cap Otherwise, contact Quantum Support. |
14400 |
|
TASK_FAILED |
Internal task failed. Details: error |
Contact Quantum Support. |
14400 |
|
TASK_START_FAILED |
Failed to start task GUID Details: error |
Contact Quantum Support. |
86400 |
|
TASK_TERMINATED |
The task GUID terminated for resourcetype:resource -> action Details: error eid |
Contact Quantum Support. |
14400 |
|
TIME_NO_SYNC_ERROR |
Nodes are not time synchronised. Time offset(s) of more than 2 seconds found. |
Contact Quantum Support. |
14400 |
|
ZOOKEEPER_FAILED_HEALTHCHECK |
zookeeper health check failed |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
|
ZOOKEEPERNODE_DOWN |
Zookeeper instance was down and has been recovered automatically. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
14400 |
Table 5: Warning events and recommended actions
|
ID |
Message and details |
Recommended action |
Dedupe interval (seconds) |
|
BLOCKSTORE_DISK_SMART_FAILURE |
Data disk device with diskid diskid: Hard disk S.M.A.R.T. status bad. |
In-situ repair of the disk will be performed. If the in-situ repair fails, then the disk will be decommissioned and will need to de replaced. Contact Quantum Support if the disk needs to be replaced. |
86400 |
|
BLOCKSTORE_IO_ERRORS |
Data disk device with diskid diskid: IO errors detected. Details: log_lines |
In-situ repair of the disk will be performed. If the in-situ repair fails, then the disk will be decommissioned and will need to de replaced. Contact Quantum Support if the disk needs to be replaced. |
86400 |
| COLD_STORAGE_USAGE_EXCEEDED_THRESHOLD_1 | Average tape usage exceeds 80%. The system is more than 80% full. You might consider expanding the system before running out of storage capacity. Our support team can help you consider your options. | Contact Quantum Support. | 86400 |
| COLD_STORAGE_USAGE_EXCEEDED_THRESHOLD_2 | Average tape usage exceeds 90%. No degradation to system functionality or redundancy is expected, but be aware that you may run out of tape storage capacity soon. The system is more than 90% full. If the current usage trend continues you will need to expand the system. Our support team can help you consider your options. | Purchase additional Cold Storage capacity. | 86400 |
|
CRON_DOWN |
cron was down and recovered automatically. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
DHCPD_DOWN |
dhcpd is down and could not be restarted |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
DISK_AUTODECOMMISSION_BACKOFF |
Autodecommission of disk device with disk id disk_id postponed. Maximum number of degraded disks reached. Details: Number of disks degraded (degraded_disks) exceeded the maximum count (max_disk_allowed) in the period of backoff_time minutes |
No action needed. |
86400 |
|
DISK_BUSLOCATION_CHANGED |
The disk with diskid diskid changed buslocation from old_buslocation to new_buslocation |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
DISK_FS_MOUNT_NOT_IN_FSTAB |
File system label and mountpoint mountpoint not in fstab. Details: file system with label label on disk device: device and diskid diskid |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
DISK_REPAIR_BACKOFF |
In-situ repair action of disk device with diskid diskid postponed. Maximum number of degraded disks reached. Details: Number of disks degraded (degraded_disks) reached/exceeded the maximum count (max_disk_allowed) in the period of backoff_time minutes. |
No action needed. |
86400 |
|
DSS_DECOMMISSIONED_DISK_WARN |
blockstore with status decommissioned for more than high_threshold days. Details: blockstore_id: blockstore_id |
Contact Quantum Support. |
86400 |
| DSS_OLDEST_LOCALIZED_OBECT_TIME_EXCEEDED_WARNING | An object was discovered which has been uploaded on {localized_date} and still has not reached full availability, which is above the threshold of {max_backlog_processing_days} days. The localized backlog is currently {number_of_objects} objects with a total size of {total_size_of_objects_in_gb} GiB | Verify the WAN link status and available bandwidth against the Localized Ingest configuration and adjust if needed. If the system takes longer than the configured time to reach full availability, please either reduce incoming/outgoing data requests or disable the Localized Ingest feature. If the backlog keeps growing indefinitely, contact Quantum Support. | 3600 |
| DSS_OLDEST_LOCALIZED_OBJECT_TIME_EXCEEDED_ERROR | An object was discovered which has been uploaded on {localized_date} and still has not reached full availability, which is above the threshold of {max_backlog_processing_days} days. The localized backlog is currently {number_of_objects} objects with a total size of {total_size_of_objects_in_gb} GiB | Verify the WAN link status and available bandwidth against the Localized Ingest configuration and adjust if needed. If the system takes longer than the configured time to reach full availability, please either reduce incoming/outgoing data requests or disable the Localized Ingest feature. If the backlog keeps growing indefinitely, contact Quantum Support. | 3600 |
|
FILESYSTEM_CLEANUP |
File system cleanup triggered. Details: File system label: label |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
FILESYSTEM_USAGE_EXCEEDED_WARNING |
File system label usage exceeded threshold of threshold% Details: File system label: label |
Contact Quantum Support. |
86400 |
|
FLAME_VERIFIER_JOB_STILL_RUNNING |
Object verifier job is running for more than the configured duration. |
If persistent, please contact QuantumSupport. |
86400 |
|
QUOTA_NOTIFICATION_LOW |
Account account_email has consumed over usage_percentage% of its allocated capacity limit of quota_gb GB. Details: Current Capacity usage of used_gb GB has exceeded usage_percentage % of the allocated quota of quota_gb GB (Usage last measured on last_updated). Quota configuration setting on this system for enforcement_type Threshold is Low: limit_low% ,High: limit_high%. |
Consider reducing capacity usage by deleting files or contact your system administrator to request additional capacity. |
86400 |
|
RAID_FS_MOUNT_NOT_IN_FSTAB |
File system mount not in fstab. Details: file system with label label on raided partition with name device |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
REPLICATION_GENERAL |
Replication error: Machine machine_name detected a general replication issue on the site site: error_message. |
Determine whether this problem is transient or network related based on the detailed error message. If you cannot resolve the problem, contact Quantum Support. |
86400 |
|
REPLICATION_QUEUE_FULL |
Replication warning: Replication queue on machine machine_name full. Reported pending replication' statistics are no longer accurate. This could be caused by a harmless temporary spike in replication traffic, indicate that replication is structurally falling behind or be a symptom of a (transient or permanent) network problem. |
Check network connectivity. If the problem cannot be identified, contact Quantum Support. |
86400 |
|
REPLICATION_THRESHOLD_EXCEEDED_COUNT |
Replication warning: Objects pending replication exceed the admin-configured threshold. There are aggregate_count objects waiting to be replicated (threshold is threshold). |
This event is most likely a transient problem. Check to see if network connectivity between the source and destination systems went down recently. Check to see if one of both systems was offline recently. Check for temporary spikes in replication traffic. Monitor the Pending Replication graphs in ActiveScale SM to ensure that the queue reduces in size over time: If the replication queue keeps growing this indicates a network problem. If the queue does not keep growing but exceeds the threshold over a long period of time, replication traffic is significantly higher than the configured threshold. Set the threshold to a higher value by changing the ActiveScale OS replication pipeline settings. If the problem cannot be identified, contact Quantum Support. |
86400 |
|
REPLICATION_THRESHOLD_EXCEEDED_SIZE |
Replication warning: Data pending replication exceeds the admin-configured threshold. There are aggregate_megabytes MB waiting to be replicated (threshold is threshold). |
This event is most likely a transient problem. Check to see if network connectivity between the source and destination systems went down recently. Check to see if one of both systems was offline recently. Check for temporary spikes in replication traffic. Monitor the Pending Replication graphs in ActiveScale SM to ensure that the queue reduces in size over time: If the replication queue keeps growing this indicates a network problem. If the queue does not keep growing but exceeds the threshold over a long period of time, replication traffic is significantly higher than the configured threshold. Set the threshold to a higher value by changing the ActiveScale OS replication pipeline settings. If the problem cannot be identified, contact Quantum Support. |
86400 |
|
SCALER_ARAKOON_KEY_COUNT_EXCEEDED |
Metadata store key count exceeded threshold |
If persistent, contact Quantum Support. |
86400 |
|
SSL_WARNING |
SSL certificate expires in less than 5 days: name |
Check the expiration date of your SSL certificate. If the certificate is expiring soon, upload and new one through ActiveScale SM. If your SSL certificate is not expiring soon, the system raised this event erroneously; contact Quantum Support. |
86400 |
|
TFTPD_DOWN |
tftpd is down and could not be restarted. |
Investigate why this event happened. If event is not caused by external event (power outage, hardware issue,É), apply documented workarounds or KB article. If no workaround or KB article exists, escalate to L3/L4. |
86400 |
|
TIME_NO_SYNC_WARN |
Nodes are not time synchronised. Time offset(s) of more than 1 second found. |
Contact Quantum Support. |
86400 |
Table 6: Informational events and recommended actions
|
ID |
Message and details |
Recommended action |
Dedupe interval (seconds) |
| BLOCKSTORE_IO_DEGRADATION |
Data disk {device} with diskid {diskid}: degradation detected. Details: diskid: {diskid}, device:{device}, buslocation:{buslocation}, serial:{serial}, type:{disktype}, size:{size} {unit}. Reason: {reason} |
Repair of the disk will be performed and a subsequent decommissioned event will be raised. No action is required at this time. |
86400 |
|
DISK_DECOMMISSIONED |
Disk device with diskid disk_id is decommissioned |
No action needed. |
86400 |
|
DISK_DETECTED_CLEAN |
New disk device with diskid detected and will get provisioned automatically. Details: diskid: diskid; buslocation: buslocation; device: device |
No action needed. |
86400 |
|
PSU_DETECTED |
New PSU (name) detected. |
No action needed. |
86400 |
|
RELENG_RECOVERED |
Reliability Engine was down and has been recovered automatically. |
No action needed. |
86400 |
